
Kubernetes Scheduling Parte 4
Kubernetes Scheduling parte 4 es la continuación del tema referente a cómo asignar Pods en los nodos. Si eres nuevo en el tema, te recomiendo que primero leas Kubernetes Scheduling parte 1, Kubernetes Scheduling Parte 2 y Kubernetes Scheduling Parte 3.
En esta ocasión, te explicaré cómo es que un Pod puede tener preferencias por elegir nodos específicos en donde ejecutarse. ¡Manos a la obra!
1. Introducción: Afinidad de Pods
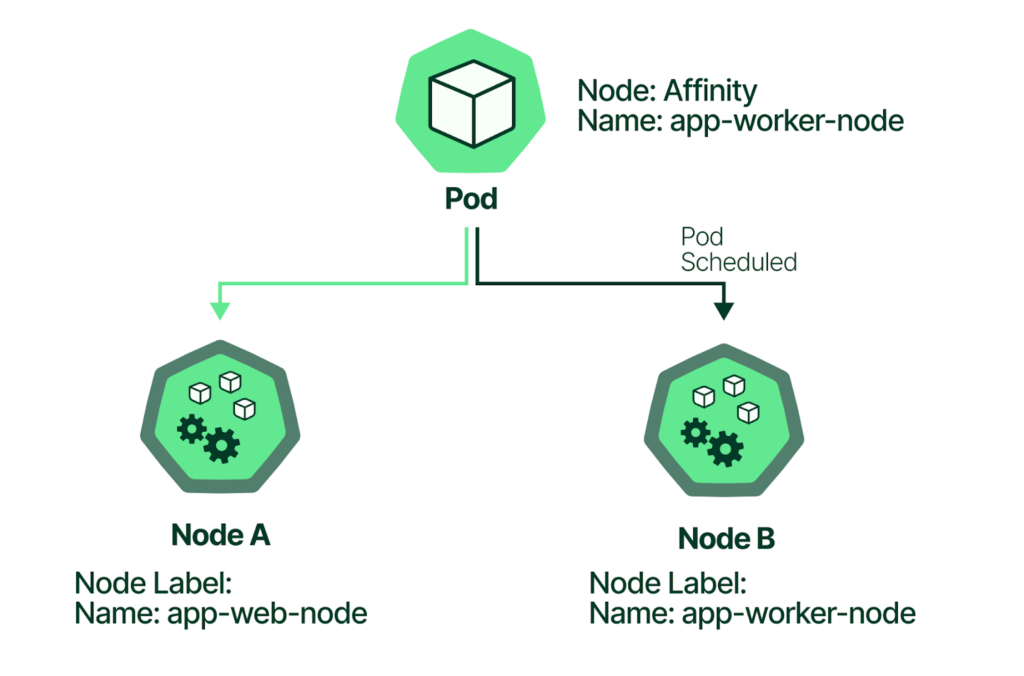
La afinidad de Pods es una característica de Kubernetes que te permite establecer reglas para determinar dónde se deben ejecutar los Pods dentro de un cluster. En pocas palabras, es como decirle a Kubernetes: «Quiero que este Pod esté cerca de otro Pod específico o en un nodo con ciertas características».
1.1. Importancia
La afinidad de Pods es crucial por varias razones:
- Colocación estratégica: Permite colocar Pods relacionados cerca unos de otros para mejorar la comunicación y el rendimiento.
- Aislamiento: Ayuda a aislar Pods que requieren recursos específicos o que deben estar separados por razones de seguridad.
- Disponibilidad: Puede utilizarse para garantizar la alta disponibilidad al replicar Pods en múltiples nodos.
Fuente de imagen
https://blog.kubecost.com/blog/kubernetes-node-affinity
1.2. Tipos de afinidad
Estos son los tipos de afinidad disponibles:
- Afinidad de nodos: Define reglas de afinidad para que un Pod se ejecute en nodos que cumplen con ciertas condiciones.
- Afinidad de pods: Define reglas de afinidad para que un Pod se ejecute con criterios de colocación, tal como dentro de un mismo nodo o zona donde ya existen otros pods con ciertas características.
- Anti-afinidad de pods: Define reglas de anti-afinidad de Pods. Esto quiere decir que evitará ejecutar un Pod en un nodo o zona donde ya existen otros pods con ciertas características.
Con kubectl se puede consultar la documentación de estos tres tipos de afinidad con el siguiente comando:
kubectl explain pod.spec.affinity
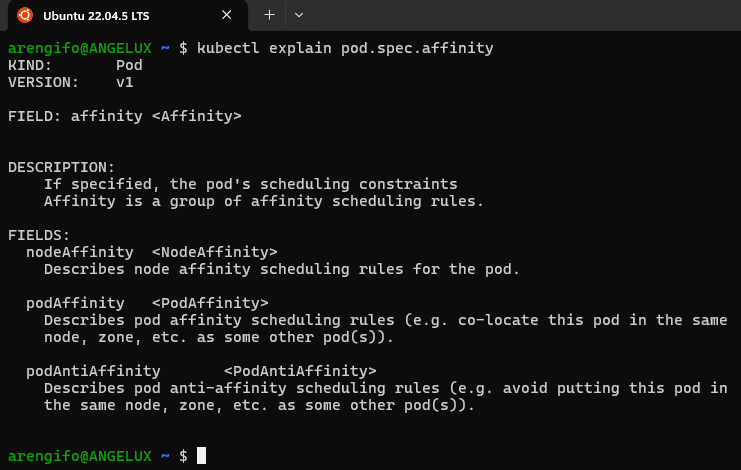
Como mencioné en un principio, en este artículo «Kubernetes Scheduling Parte 4» solo me centraré en el primer tipo de afinidad: la de nodos, conocida como nodeAffinity.
1.3. ¿nodeAffinity o nodeSelector?
Tanto nodeSelector como nodeAffinity son mecanismos en Kubernetes que permiten controlar dónde se ubican los Pods dentro de un cluster. Sin embargo, presentan algunas diferencias importantes en su funcionamiento y flexibilidad.
- nodeSelector: Es una forma más simple de asignar Pods a nodos específicos. Funciona mediante etiquetas (labels) que se asignan a los nodos. Un Pod con un
nodeSelectorsolo se programará en un nodo que tenga las etiquetas correspondientes.- Es menos flexible que
nodeAffinityya que solo permite una correspondencia exacta entre las etiquetas del Pod y las etiquetas del nodo. - Es ideal para casos en los que se necesita una asignación básica y estática de Pods a nodos, como por ejemplo, colocar Pods que requieren hardware específico (GPUs, etc.) en nodos que tengan ese hardware.
- Es menos flexible que
- nodeAffinity: Es más potente y flexible que
nodeSelector. Permite definir requisitos más complejos para la ubicación de los Pods, utilizando operadores comoIn,NotIn,Existsy combinaciones de ellos.- Ofrece una mayor granularidad en la definición de las reglas de afinidad. Por ejemplo, puedes especificar que un Pod debe estar en un nodo que tenga una etiqueta específica O que no tenga otra etiqueta.
- Es ideal para casos de uso más complejos, como:
- Tolerancia a fallos: Asegurar que los Pods se distribuyan en múltiples nodos para evitar que una falla en un nodo afecte a todos los Pods.
- Colocación estratégica: Agrupar Pods relacionados para mejorar la comunicación y el rendimiento.
- Aislamiento: Separar Pods que requieren diferentes niveles de seguridad o recursos.
2. Especificación de nodeAffinity
Si te fijas, en especificación de nodeAffinity (kubectl explain pod.spec.affinity.nodeAffinity), verás que existen dos tipos posibles:
- preferredDuringSchedulingIgnoredDuringExecution: Afinidad suave y preferente. El Scheduler intentará o preferirá colocar los pods según una o más reglas de preferencias, según los pesos que se configuren. Pero, si no se logra encontrar un nodo que se ajuste a las preferencias, se colocará el pod en otro nodo inclusive si no coincide con las características preferidas.
- requiredDuringSchedulingIgnoredDuringExecution: Afinidad fuerte y obligatoria. El Scheduler buscará colocar los pods según con características específicas. Si no encuentra ningún nodo que se ajuste a las cualidades deseadas, el pod se quedará en estado Pending indefinidamente hasta que en algún momento aparezca que sí cumpla con las características solicitadas.
En ambos casos, el Scheduler realiza la búsqueda y elección del nodo solo cuando el pod se crea. Una vez que el pod ya fue colocado en un nodo y está en ejecución, se ignora las preferencias de nodos incluso si estos dejan de cumplir con las características deseadas. Es decir, los pods no son expulsados del nodo si este deja de cumplir con las características elegidas en un inicio.
2.1. Características de nodos
Lo que he venido hablando como «características» de los nodos, no es más que dos criterios diferentes para seleccionar uno o más nodos, los cuales son:
- matchExpressions: Usa labels o etiquetas de los nodos para la selección. Ejm:
zone=us-east-1a,arch=amd64 - matchFields: Utiliza campos o atributos de los nodos para la selección. Ejm:
metadata.name=worker03,status.phase=Running
En ambos casos, se utilizan pares de tipo clave/valor (key/value).
2.2. Selección de nodos por clave/valor
Ya sea que se seleccione nodos con matchExpressions o matchFields, se utilizan pares de tipo clave/valor (key/value) junto con un operador.
Para una clave o key específica, se puede indicar uno o más posibles valores sobre los cuales se aplica un operador que puede ser DoesNotExist, Exists, Gt (greater-than o mayor-que), In (está en una lista de posibles valores), Lt (less-than o menor-que) o NotIn (no está en una lista de posibles valores).
3. Ejemplos de nodeAffinity
Este artículo «Kubernetes Scheduling Parte 4» puede resultar algo denso y difícil de comprender para un lector que interactúa con este tema por primera vez. Por eso, voy a mostrar una serie de ejemplos diferentes de configuración de afinidad de nodos usando archivos de manifiestos con los campos/atributos explicados anteriormente.
3.1. Afinidad fuerte con nodos de discos SSD
El Pod se programa solo en nodos con la etiqueta disktype=ssd
apiVersion: v1
kind: Pod
metadata:
name: ejemplo-1
spec:
containers:
- name: main
image: alpine
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
3.2. Afinidad fuerte con nodos en zona distinta a us-west-1c
El Pod se programa solo en nodos que no tengan la etiqueta zone=us-west-1c
apiVersion: v1
kind: Pod
metadata:
name: ejemplo-2
spec:
containers:
- name: main
image: alpine
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: NotIn
values:
- us-west-1c
3.3. Afinidad suave con nodos de más de 4 CPUs
Se intenta o prefiere colocar el pod en nodos que tengan más de 4 CPUs, según el valor de la etiqueta cpu-count
apiVersion: v1
kind: Pod
metadata:
name: ejemplo-3
spec:
containers:
- name: main
image: alpine
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 5
preference:
matchExpressions:
- key: cpu-count
operator: Gt
values:
- "4"
3.4. Afinidad suave con nodos de nombres específicos
Se intenta o prefiere colocar el pod en nodos de nombre worker-01 o worker-07, según el valor del campo metadata.name
apiVersion: v1
kind: Pod
metadata:
name: ejemplo-4
spec:
containers:
- name: main
image: alpine
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 3
preference:
matchFields:
- key: metadata.name
operator: In
values:
- worker-01
- worker-07
3.5. Afinidad suave con nodos pequeños en zonas específicas
Se intenta o prefiere colocar el pod en nodos que tengan a lo mucho 16 GB de memoria y que estén en las zonas us-east-1c, us-east-1d o us-east-1f
apiVersion: v1
kind: Pod
metadata:
name: ejemplo-5
spec:
containers:
- name: main
image: alpine
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
matchExpressions:
- key: memory-size
operator: Lt
values:
- "16Gi"
- weight: 5
preference:
matchExpressions:
- key: zone
operator: In
values:
- us-east-1c
- us-east-1d
- us-east-1f
Conclusión
«Kubernetes Scheduling Parte 4» es tal vez uno de los posts más detallados que he escrito hasta el momento. Esto es así porque el tema lo amerita.
Kubernetes es muy potente y flexible, pero ello viene con un precio asociado: mayor complejidad.
Con este artículo he buscado que el tema de Scheduling de Pods según la afinidad con nodos sea lo más fácil de entender, aun sabiendo que existen muchas opciones y combinaciones diferentes de configuración.
Los ejemplos mostrados han intentado explicar de forma práctica lo que de otro modo hubiera tenido que hacerlo con muchos más párrafos extensos y teóricos.
Si el artículo te es de utilidad, o conoces a alguien que le pueda servir, no dudes en compartirlo.


Deja un comentario