



Git desde cero – parte 3
En este artículo Git desde cero – parte 3, voy a explicar sobre el significado de las ramas o branches, su propósito y cómo se usan en conjunto con otros comandos comunes.
¿Aún eres nuevo en Git y llegaste aquí por casualidad? Entonces, quizá te interese leer la parte 1 y/o la parte 2 de esta serie de artículos que enseñan el uso de esta herramienta paso a paso.
Introducción a las ramas
Imagina que estás trabajando en un proyecto escolar con tus amigos, y todos quieren agregar diferentes cosas al mismo tiempo. Para evitar que todo se vuelva un caos, cada uno decide trabajar en su propia versión del proyecto llamada «rama» (branch).
Entonces, si tú y tus amigos están creando una presentación, cada uno podría tener su propia rama para trabajar en sus diapositivas sin afectar el trabajo de los demás.
Las ramas en Git funcionan de manera similar. Son como caminos separados donde puedes hacer cambios en tu código sin afectar el código principal (llamado rama principal o «master»). Esto es genial porque puedes probar nuevas ideas sin arruinar lo que ya funciona. Cuando estás listo y todo funciona bien en tu rama, puedes fusionarla de nuevo con la rama principal para que todos vean tu trabajo.
Entonces, resumamos: las ramas en Git son como versiones paralelas de tu proyecto. Te permiten trabajar en nuevas funciones o arreglos sin dañar el trabajo principal y, cuando todo está listo, puedes unirlo para que todos lo disfruten. ¡Es como tener tu propio espacio creativo en un proyecto compartido!
Manos a la obra: A trabajar con ramas
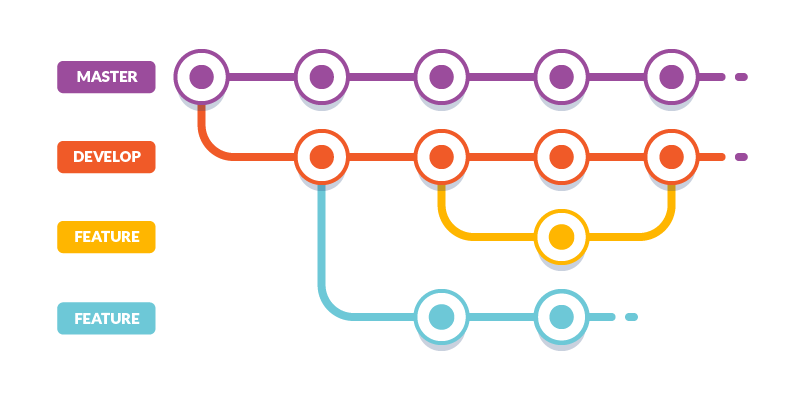
Como se ve en la imagen de arriba, esta es una representación de un proyecto con cuatro ramas: master, develop y dos feature (naranja y cyan).
También, se puede notar cómo unas ramas derivan o se ramifican a partir de otra. De modo similar, en cierto punto, una rama se integra o fusiona con otra. Este flujo es el normal y esperado en un proyecto Git.
Esto sucede así porque conforme un proyecto va creciendo en complejidad, puede ser probable que más de una persona trabaje en él. Eso conlleva a la división de tareas que en conjunto deben llevar a un resultado final de múltiples funcionalidades integradas. Por ello, dichas tareas tendrán que ser avanzadas en paralelo sin dañar la versión principal y estable del proyecto. Cuando la tarea ya esté casi culminada, muy probablemente necesitará fusionarse con la rama principal u otra rama distinta.
Entonces, por lo antes explicado, es vital saber cómo trabajar con diferentes branches. Así que como esto es una guía de Git desde cero, vamos a ver los comandos más comunes para estos fines.
1. Clonar el repositorio
Siguiendo la secuencia explicada en las partes uno y dos de este artículo, Angel inicializó el repositorio Git «infra-como-codigo» y subió contenido a él. Ahora, es turno que Ana se integre con Angel para trabajar en el mismo proyecto. Por ello, Ana debe clonar el mismo repositorio en su equipo local:
git clone https://github.com/arengifoc/infra-como-codigo.git
Cuando se clona un repositorio, uno accede a la rama principal por defecto.
2. Crear una rama a partir de la principal
¿No sabes cuál es la rama principal de un repositorio? Mira este tip que te dice cómo.
Ahora, creamos una rama con un nombre cualquiera, como por ejemplo «trabajo-ana»:
git checkout -b trabajo-ana
Este comando no solo crea la nueva rama, sino que también nos cambia a la misma. Podemos verificar la rama actualmente en uso así:
git branch
Hasta aquí, ¿qué te parece el artículo Git desde cero – Parte 3? No te desanimes y sigue leyendo.
3. Hacer cambios al repositorio
Ahora nos toca hacer los cambios que deseemos en el contenido del repositorio. Por ejemplo, agregamos un comentario en la primera línea del archivo y luego otras dos líneas de comentario al final del archivo. Esto se puede hacer con cualquier editor preferido.
En mi caso, estaré agregando en el archivo main.tf el texto «# Modulo de creacion de bucket S3» al principio, y «# linea 1» y «# linea 2» al final.
4. Mostrar diferencias detectadas tras modificación
Tras guardar cambios en main.tf y cerrar el editor, ahora podemos ver el estado de Git en el repositorio:
git status
Deberíamos ver algo como esto:
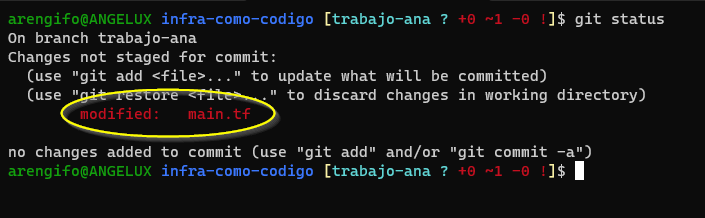
Git nos informa que el archivo main.tf ha sido modificado. ¿Queremos ver el detalle de la modificación? Esto se hace con el siguiente comando que muestra las diferencias:
git diff main.tf
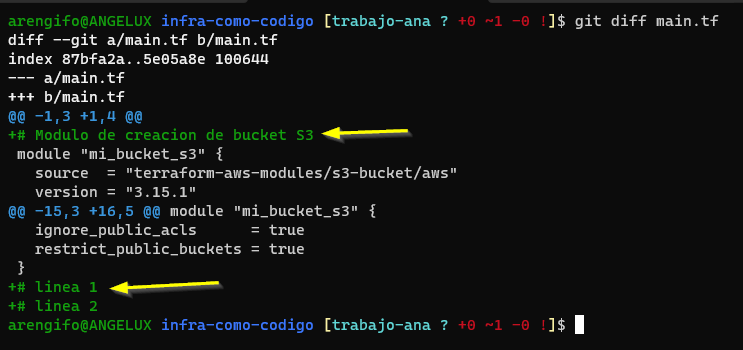
Las flechas amarillas resaltan las modificaciones detectadas. Git muestra de color verde las líneas que son agregadas con un prefijo «+»
¿Cómo vas hasta ahora? ¿Se entiende esta guía de Git desde cero – Parte 3? Sigamos, entonces.
5. Agregar y confirmar cambios
Ahora debemos hacer algo que aprendimos en artículos previos. Esto es, agregar los archivos al área de preparación (staging) y luego confirmar los cambios con una operación commit.
git add main.tf git commit -m "Agregado comentarios explicativos a main.tf"
6. Publicar cambios en el repositorio remoto
Acerca del servidor remoto de un repositorio
En Git, un servidor remoto, comúnmente denominado «origin,» es una referencia a un repositorio remoto en el que se almacenan los archivos de tu proyecto. Este repositorio remoto puede encontrarse en una plataforma de alojamiento como GitHub, GitLab, Bitbucket u otro servidor Git accesible a través de una URL.
¿Por qué es importante esto? Porque es hacia el servidor remoto donde enviamos los cambios con el comando git push. Es solo que hasta el momento no éramos concientes de esto pues solo usamos dicho comando sin hacer ninguna mención a dicho «origin».
Visualizando la rama remota configurada
Pero, cuando creamos una rama nueva, Git no asume cuál es el servidor remoto al cual se debe enviar los cambios hechos en esta nueva rama sino hasta que configuremos una predeterminada. ¿Cómo puede verse ese valor? Así:
git branch -v
Esto debería lucir así:

Las salida del comando se interpretan por columnas, de izquierda a derecha, así:
- Nombre de rama (
mainotrabajo-ana) - ID corto del último commit en la rama
- Entre corchetes, el nombre de la rama en el servidor remoto donde se envían los cambios
- Mensaje del último commit en la rama
Si te percatas, en la rama trabajo-ana, luego del ID corto de commit no figura ningún valor entre corchetes, sino el mensaje. Esto nos da a entender que no hay aún rama del servidor remoto configurada para la rama en el repositorio local.
¿Y por qué tanto énfasis en esto? ¿No puedo simplemente ejecutar git push y listo? Pues, probemos:
git push
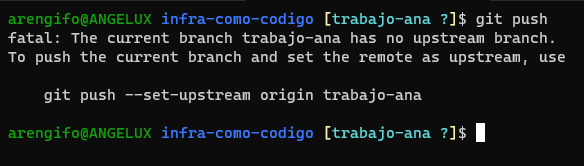
Ahora queda comprobado que se requiere hacer algo más y el mensaje nos sugiere qué hacer.
La explicación nos dice que no hay rama remota configurada para la rama actual del repositorio local. Esto se le conoce simplemente como upstream branch.
Configurando la rama remota
Por única vez en la vida de una rama local se debe configurar la rama remota o upstream a la vez que se envía los cambios (push) de este modo:
git push --set-upstream origin trabajo-ana
O su equivalente en forma corta, así:
git push -u origin trabajo-ana
Luego, consultamos la información de la rama remota configurada:
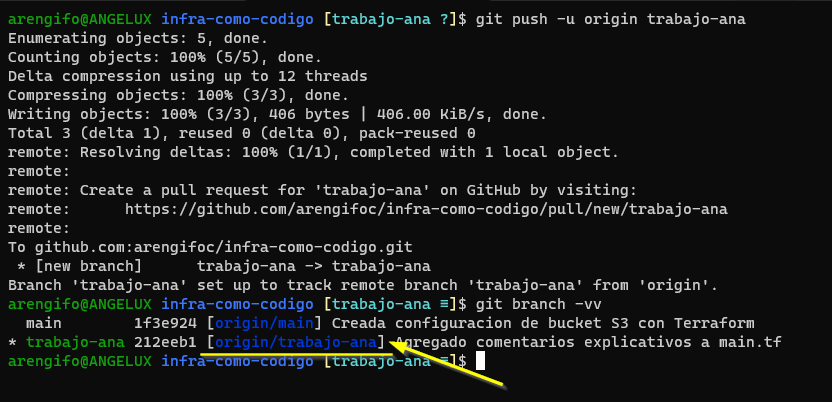
La imagen anterior nos informa del primer comando que:
- Se ha creado (ver
[new branch]) la rama del mismo nombre en el servidor remoto. - Se fijó la rama
trabajo-analocal para que rastree los cambios en la rama del mismo nombre en el servidor remoto «origin». - Sugiere que se debe crear un «Pull Request» apuntando a la URL que indica la pantalla. Esto será explicado en el siguiente artículo, pero por mientras puedes informarte un poco al respecto leyendo este enlace.
También, del segundo comando nos informa que ahora sí detecta un nombre de rama remota configurada para la rama local (ver texto subrayado en amarillo).
Conclusión
En el post de hoy hemos revisado conceptos importantes como son las ramas, su razón de uso y cómo son parte del día a día del trabajo en equipo. Luego, revisamos lo que son los servidores remotos, ramas remotas y la relación con las ramas del repositorio local. Por último, exploramos en detalle los diferentes comandos usados en cada caso hasta el punto de haber publicado nuestros cambios en el servidor remoto usando una rama nueva.
Esta guía Git desde cero – Parte 3 ha sido un esfuerzo continuo por cubrir las diferentes situaciones a las que cualquier principiante se enfrentaría cuando empieza a trabajar con Git. El objetivo es que se aprenda no solo comandos de memoria, sino que se comprenda el porqué de cada uno y así saber cuándo usarlos en diversas situaciones.
Si te gustó el artículo, no dudes en compartirlo y/o dejarme tus comentarios. Nos encontramos en una próxima oportunidad.

Deja un comentario